Построение ансамблей моделей
Ансамбль методов в статистике и обучении машин использует несколько обучающих алгоритмов с целью получения лучшей эффективности прогнозирования, чем могли бы получить от каждого обучающего алгоритма по отдельности.
- Ансамбли более гибкие, они обладают большим числом параметров, чем отдельные модели.
- В теории, из-за этого они склонные переобучаться, но на практике наоборот.
Простое усреднение
Блендинг или усреднение (можно взвешенное)
Устредняем результаты нескольких моделей.
Бэггинг
Бэггинг – технология классификации, где в отличие от бустинга все элементарные классификаторы обучаются и работают параллельно (независимо друг от друга). Идея заключается в том, что классификаторы не исправляют ошибки друг друга, а компенсируют их при голосовании. Базовые классификаторы должны быть независимыми, это могут быть классификаторы основанные на разных группах методов или же обученные на независимых наборах данных. Во втором случае можно использовать один и тот же метод. Бэггинг позволяет снизить процент ошибки классификации в случае, когда высока дисперсия ошибки базового метода.
Метод бэггинга (bagging, bootstrap aggregation) был предложен Л. Брейманом в 1996 году.
Пример с сайта XGBoost
- Помогает против переобучения.
- Улучшает качество.
- Хорошо распараллеливается.
- Требует больше времени.
- Не используется весь набор данных.
- Параметры выборки по строкам (или бустраппинг).
- Параметры выборки по столбцам.
- Количество моделей.
- Перемешивание.
- Параметры моделей.
Назовите очень известный алгоритм машинного обучения, построенный по принципе бэггинга.
Бустинг
Бустинг (англ. boosting — улучшение) — это процедура последовательного построения композиции алгоритмов машинного обучения, когда каждый следующий алгоритм стремится компенсировать недостатки композиции всех предыдущих алгоритмов.
Все началось с вопроса о том, можно ли из большого количества относительно слабых и простых моделей получить одну сильную. Оказалось, можно.
В течение последних 10 лет бустинг остаётся одним из наиболее популярных методов машинного обучения, наряду с нейронными сетями и машинами опорных векторов. Главную роль в популяризации бустинга сыграли ML соревнования, в особенности kaggle. Основные причины — простота, универсальность, гибкость (возможность построения различных модификаций), и, главное, высокая обобщающая способность.
Бустинг над решающими деревьями считается одним из наиболее эффективных методов с точки зрения качества классификации.
Основные виды бустинга:
- Основанные на весах
- Основанные на остатках
Примерно так работает AdaBoost — первый популярный алгоритм бустинга. Подробнее о нем здесь
Про настройку гиперпараметров ансамблей моделей машинного обучения
Под катом хочется затронуть тему настройки гиперпараметров в моделях машинного обучения, получаемых при помощи блендинга. В таких ансамблях предсказания из одной модели машинного обучения становятся предикторами для другой (следующего уровня). На рисунке ниже представлены некоторые варианты ансамблей, где данные передаются слева направо. Называть такие ансамбли мы будем в рамках поста также пайплайнами или композитными моделями (композитные пайплайны).
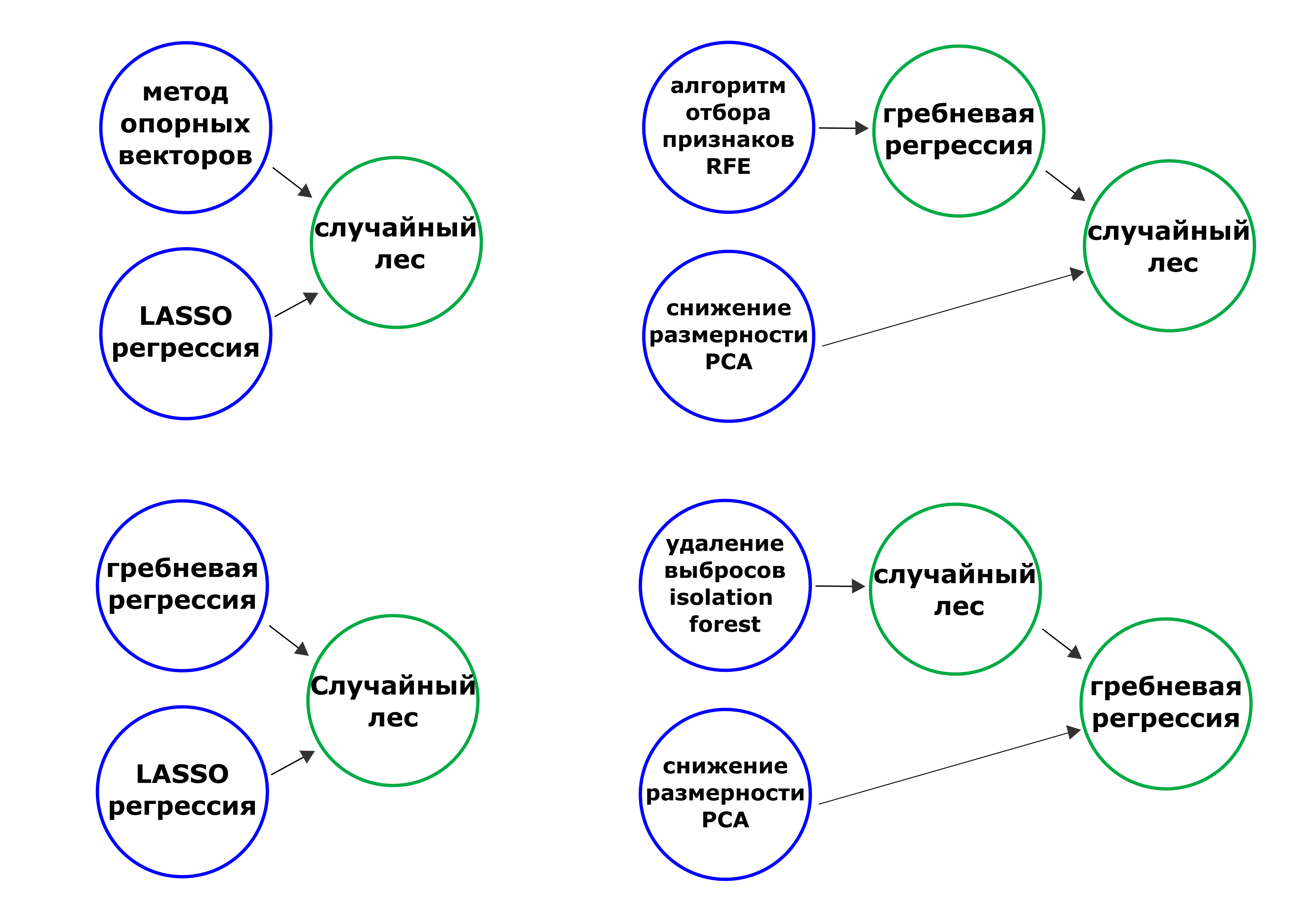
Рисунок 1. Примеры ансамблей различной структуры и содержания (см. названия операций в узлах).
От использования таких сложных композитных структур может уменьшаться ошибка прогноза. Модели иногда становятся более робастными. Однако, существует и обратная сторона — за высокую эффективность приходится платить “прожорливостью ансамбля” (времени и вычислительных ресурсов на ансамбль тратится гораздо больше, чем для одиночных моделей). Также чем сложнее пайплайн, тем сложнее его настраивать. Вот про то, как можно в таких ансамблях производить настройку гиперпараметров мы и поговорим.
Дисклеймер: мы не обсуждаем конкретные методы оптимизации, например байесовскую оптимизацию, случайный поиск, или эволюционные алгоритмы (или какие-либо ещё алгоритмы). Здесь обсуждаются более верхнеуровневые подходы к настройке гиперпараметров независимо от алгоритмов, используемых в ядре. В примерах из данного поста используется байесовская оптимизация при помощи библиотеки hyperopt, однако она может быть заменена на более подходящую (вам или нам) при необходимости.
Как эту задачу решают в свободной индустрии
Очевидно, очень по-свободному.
Ну достаточно шуток, — русскоязычных материалов на тему подготовки ансамблей из моделей машинного обучения относительно немного. Начать, полагаю, стоит с “Cтекинг (Stacking) и блендинг (Blending)”. Затем продолжим изучение темы с “Построение ансамблей моделей” и “Машинное обучение: ансамбль смешивания на Python” (тут настройка кстати гиперпараметров не производится), заглянем в англоязычный интернет и, наконец, пробежимся по готовым решениям победителей и участников kaggle соревнований.
Из работ выше можем резюмировать следующий классический подход. Сначала обучаются и настраиваются все одиночные модели первого уровня, — затем уже ансамблирующая модель (модели). Затем процесс повторяется, получается такое итеративное продвижение слева направо. Такой же подход эксплуатируется в “Hyperparameter Tuning the Weighted Average Ensemble in Python”, где настраиваются только веса ансамбля.
В тетрадке с kaggle “A Data Science Framework: To Achieve 99% Accuracy” система такая же: гиперпараметры настраиваются у каждой модели по отдельности. Тем не менее, даже кагглеры-чемпионы отмечают, что настраивать гиперпараметры в ансамблях, дело, тем не менее, нетривиальное: “We could have experimented with more hyperparameters in our detection models as well. I really dislike hyperparameter tuning (never really developed a good strategy for it) and often try and compensate by ensembling different models together.” © [1st place] Solution Overview & Code.
Как эту задачу решают в душной академии
Очевидно, очень по-душному.
Вот где информации и подходов навалом, так это в научных статьях, в которых ещё и как правило не имеется ни ссылок на программные реализации алгоритмов, ни на репозиторий с экспериментами. Еще заметим, что информации из отечественных статей на эту тему найти не удалось (честно, всю первую страницу поиска в google scholar протыкал — ничего не нашёл), поэтому сразу перейдём к англоязычным источникам.
Достойным упоминания сочтём подход “ничего не делать” — при таком подходе веса у ансамбля (если это взвешенное ансамблирование) не настраиваются вовсе. Все модели первого уровня включаются в ансамбль с одинаковыми весами. Однако, такой метод не всегда оптимальный (см. Stacked ensemble combined with fuzzy matching for biomedical named entity recognition of diseases). Естественно, данный подход нельзя отнести к методам настройки гиперпараметров, поэтому перейдём к настоящим методам.
Начнем с классического подхода “сначала настраивается каждая модель по отдельности, затем — веса у ансамбля”. Такой подход описан, например в Optimizing ensemble weights and hyperparameters of machine learning models for regression problems, где его оптимальность, стоит заметить, подвергается сомнению. Собственно, даже в рамках этой статьи авторы предлагают более перспективную альтернативу — настраивать гиперпараметры моделей и веса ансамбля одновременно.
В Hyperparameters tuning of ensemble model for software effort estimation используется точно такой же подход, только обобщенный для стекинга, когда финальные предсказания объединяются не взвешиванием, а моделью. Поскольку пространство поиска получилось в их случае достаточно большим, для оптимизации использовались метод роя частиц и генетический алгоритм.
В целом встречается довольно много вариаций на описанные выше несколько подходов, но принципиально разных методов всего два: настройка базовых моделей по отдельности и настройка всех моделей в ансамбле одновременно.
Какие подходы мы в итоге выделили
Отметим, что все вышеперечисленные изыскания мы проводили для того, чтобы улучшить модуль настройки гиперпараметров в нашем open-source AutoML фреймворке FEDOT. Такой типичный пример работы R&D: мы хотели улучшить модуль настройки гиперпараметров и нужно было выбрать один, самый подходящий подход. В таком случае нужно 1) определить конкурирующие решения, 2) реализовать прототипы подходов, 3) провести оценку и 4) выбрать лучший (по заданным критериям) и 5) интегрировать выбранный подход в проект.. Когда мы провели обзор подходов, мы реализовали в рамках выбранной ветки три подхода к настройке гиперпараметров. А затем провели эксперименты с целью определения наиболее удачного подхода. Критерии успешности подхода выделим для начала два: алгоритм настройки должен работать быстро и точно, то есть ошибка ансамбля после настройки гиперпараметров должна быть меньше, чем с параметрами по умолчанию.
Не будем тянуть интригу — каких же трёх красавцев мы приготовили (названия придуманы автором):
Обсудим теперь каждую стратегию в отдельности. Для большей наглядности будем использовать анимации. Первой пойдёт изолированная (Анимация 1).
Анимация 1. Демонстрация настройки гиперпараметров при помощи изолированного подхода.
Красным цветом подсвечиваются узлы, в которых производится настройка гиперпараметров и стрелками показано, через какие узлы передаются данные. Из анимации видно, что на каждой итерации настраивается только один узел. При этом метрика ошибки измеряется по предсказаниям, получаемых из данного узла. Это означает, что на одной итерации данные передаются только через узлы-предки настраиваемой модели. При такой стратегии соблюдается принцип “одна итерация — обучение одной модели”.
Теперь перейдём к аналитике. К плюсам приведенного подхода относится вычислительная эффективность. Действительно, на каждой итерации не требуется обучать все модели пайплайна заново.
Но ключевыми являются именно недостатки. Первый и самый главный, это узкоспециализированность алгоритма — он работает только на тех узлах, вывод которых можно сопоставить с целевой переменной и получить метрику, то есть только на моделях. Если в структуре пайплайна присутствуют операции предобработки (например алгоритм отбора признаков, или алгоритм снижения размерности методом главных компонент), то применить данный подход невозможно. Раз вывод некоторых узлов невозможно напрямую сопоставить с целевой переменной для оценки ошибки, то такие операции настроить не получится. Решить эту проблему можно отчасти решить при помощи включения дополнительных правил: например можно игнорировать такие случаи, или настраивать гиперпараметры предобработок совместно с параметрами моделей-потомков. Однако данные модификации требуют времени на внедрение, поэтому мы их решили отложить до того момента, пока не убедимся, что подход является наиболее перспективным — прототип обошелся без этого.
Вторым минусом является специфика самого подхода. Алгоритм то — жадный. Мы на каждом шаге занимаемся тем, что пытаемся получить локально оптимальную конфигурацию гиперпараметров для каждого подграфа большого пайплайна. Нет никаких гарантий, что в погоне за оптимумом на каждом шаге мы не проскочим глобальный для всего пайплайна.
Недостатки первого подхода (хотя бы некоторые из них) может решить второй — последовательная настройка (Анимация 2).
Анимация 2. Демонстрация настройки гиперпараметров при помощи последовательной стратегии.
В данном подходе данные пропускаются уже целиком через весь пайплайн на каждой итерации (красные стрелочки светятся у всего пайплайна), хотя по прежнему оптимизируются гиперпараметры только у одной операции.
Возможность оптимизировать пайплайн любой структуры, в том числе содержащий операции предобработки;
На каждой итерации сопоставляются вывод композитной модели целиком. Следовательно, модель оптимизируется по финальным, а не промежуточным предсказаниям.
Но есть и минусы. Поскольку мы начинаем идти слева направо, то получается, что во время оптимизации гиперпараметры предшествующих моделей подстраиваются под одну конфигурацию последующих (потомков). А уже на следующем узле, конфигурация потомка меняется на новую. Возможно, это и не самая большая проблема, ведь всегда можно оставить исходные значения гиперпараметров у узлов-потомков, если любые другие сочетания не приводят к улучшению метрики.
Однако продвигаясь последовательно мы сужаем пространство поиска, поскольку прошедшие ранее оптимизацию узлы не могут уже изменять назначенные гиперпараметры. Таким образом мы сами можем себя загнать себя в “неоптимальный угол” и несмотря на то, что оптимизировать финальную ансамблирующую модель мы ещё можем, ничего улучшить не выйдет. Мне в голову приходит аналогия с тортом, который люди передают по цепочке, откусывая при этом по кусочку. Последнему в этой очереди может ничего не достаться — хотя именно он, возможно, мог раскрыть секрет его приготовления и тогда не пришлось бы никогда стоять в очереди за тортами.
Коллеги: Как же преодолеть проблемы предыдущих подходов?
Я: Да просто сгрузим всё в кучу!
Так и поступили. На Анимации 3 показано, что можно оптимизировать весь пайплайн как один большой “черный ящик”, где набор гиперпараметров пайплайна равен объединению наборов параметров моделей в его структуре.
Анимация 3. Демонстрация алгоритма одновременной настройки гиперпараметров.
Оптимизируется значение метрики для всего пайплайна целиком;
В ходе оптимизации пространство поиска не уменьшается — есть возможность одновременно менять гиперпараметры как у корневой модели, так и у предшествующих;
Минусы, вытекающие из преимуществ подхода:
Самый вычислительно дорогой способ;
Очень большое пространство поиска, особенно для больших разветвленных ансамблей.
В общем, третий подход кажется наиболее эффективным для задачи нахождения оптимальных сочетаний гиперпараметров в ансамбле, — проверим это!
Эээксперименты
Итак, выберем наиболее подходящий подход для его внедрения. Для этого поставим эксперимент следующим образом (Таблица 1). Важное уточнение: финальные метрики измеряются на отложенной выборке, к которой тюнер не имел доступ во время оптимизации.
Таблица 1. Постановка эксперимента. Поскольку Байесовская оптимизация может на разных запусках сходиться к разным решениям, запуски повторяются по 30 раз, чтобы получить более достоверные результаты как по метрикам, так и по времени работы.
Количество таблиц, на которых будет производиться проверка
3 для классификации и 3 для регрессии
Количество пайплайнов, гиперпараметры которых будут оптимизироваться
3 штуки разного размера для каждой задачи
Количество итераций, выделяемых тюнеру для оптимизации
20 и 100 итераций
Время расчетов (секунды), ROC AUC для классификации и SMAPE для регрессии
На картинке ниже (Рисунок 2) показаны три пайплайна различной разветвленности, которые участвовали в экспериментах.
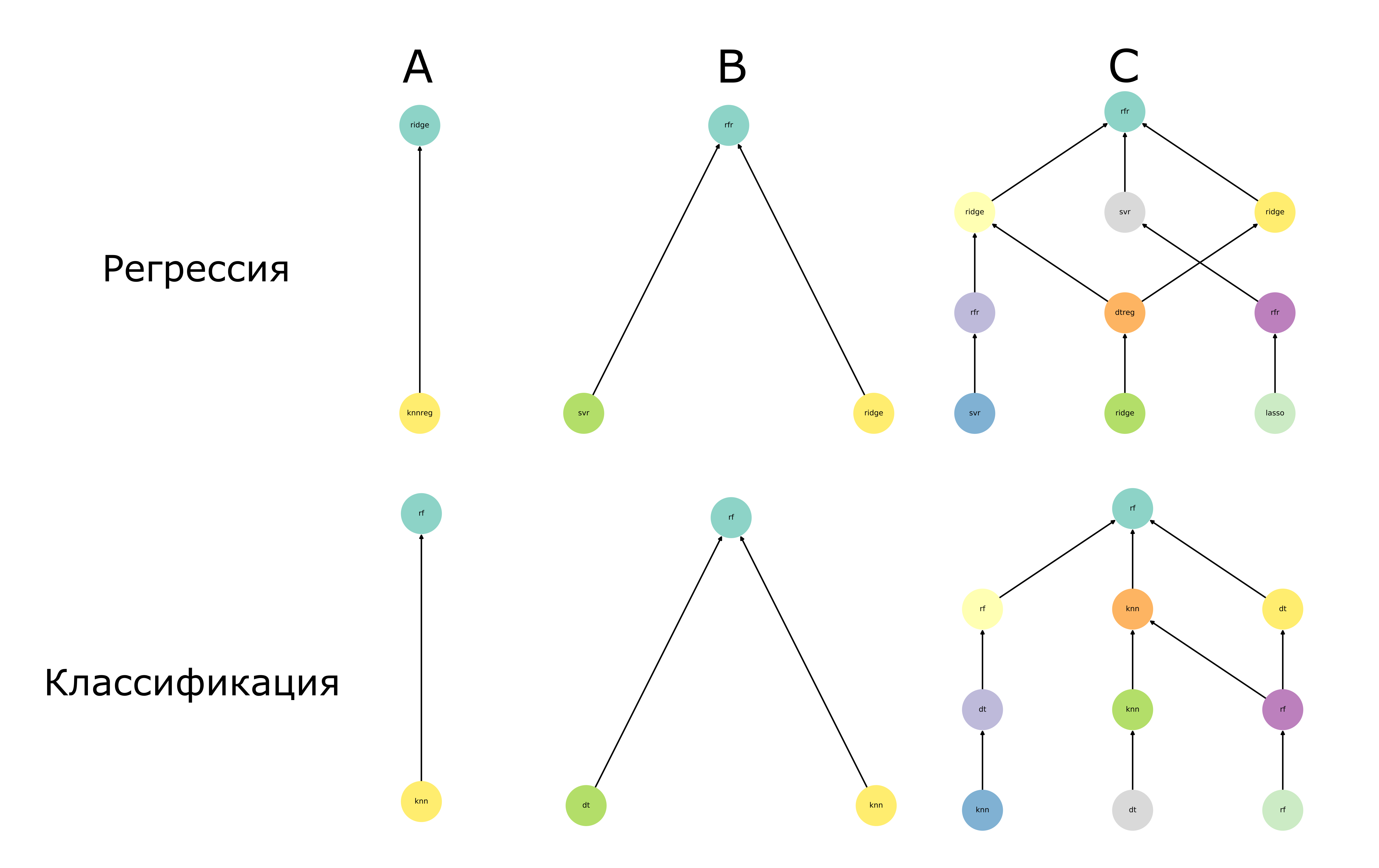
Рисунок 2. Оптимизируемые в экспериментах пайплайны. Показаны три пайплайна для регрессии и три пайплайна для задачи классификации. Данные в пайплайнах на данном рисунке передаются снизу вверх.
Количество операций (моделей) в структуре пайплайнов варьировалось от двух (пайплайн A) до десяти (пайплайн C). Расшифровка названий моделей: ridge — гребневая регрессия, lasso — LASSO регрессия, knnreg — K-ближайших соседей для задачи регрессии, svr — метод опорных векторов для задачи регрессии, rfr — случайный лес для регрессии, dtreg — решающее дерево для задачи регрессии, knn -K-ближайших соседей для задачи классификации, rf — случайный лес для классификации, dt — решающее дерево для задачи классификации.
Результаты эээкспериментов
Как мы и писали выше, сравнение будет производиться по двум критериям: время работы и метрики на отложенной выборке. С метрикой на отложенной выборке также введем дополнительный критерий — чем более стабильный (по 30 запускам) результат будет получен, тем метод предпочтительней. То есть будем смотреть не только на среднее значение метрики, но и на разброс. Помимо этого мы также посмотрим на каких типах пайплайнов рассматриваемые подходы работают лучше: на простых линейных A; относительно простых, но разветвленных B, и на сложных многоуровневых C. Также сделаем выводы о том, влияют ли объем выделяемых вычислительных ресурсов (определяется количеством итераций) на эффективность подхода.
Важная оговорка. Поскольку нам не интересно насколько хорошо могут прогнозировать пайплайны типов A, B или C, а перед нами стоит задача выяснить эффективность алгоритмов настройки параметров, то ниже мы будем говорить о приросте в метриках (а не абсолютных значениях). Для симметричной абсолютной процентной ошибки (SMAPE) дельта будет рассчитываться как разность между значением метрики до тюнинга и значением метрики после. Для классификации будем вычитать из метрики после тюнинга метрику до настройки гиперпараметров. Таким образом, для всех задач будет справедливо утверждение “чем больше дельта, тем лучше алгоритм”.
Дисклеймер: приведенные ниже выкладки не тянут на полноценное научное исследование, а проводились в будничном режиме в процессе разработки. Подобный бенчмаркинг применялся нами при прототипировании. Поэтому, если захотите написать научную статью в Q1-журнал на подобную тему, экспериментов придется провести несколько больше: и метрик рассчитать придётся побольше, и датасетов взять штук эдак 10-15 для каждой задачи, формализовать гипотезу, провести статистическое тестирование и т.д.
Итак, результаты сравнения улучшения по метрикам для задачи регрессии представлены на Рисунке 3.
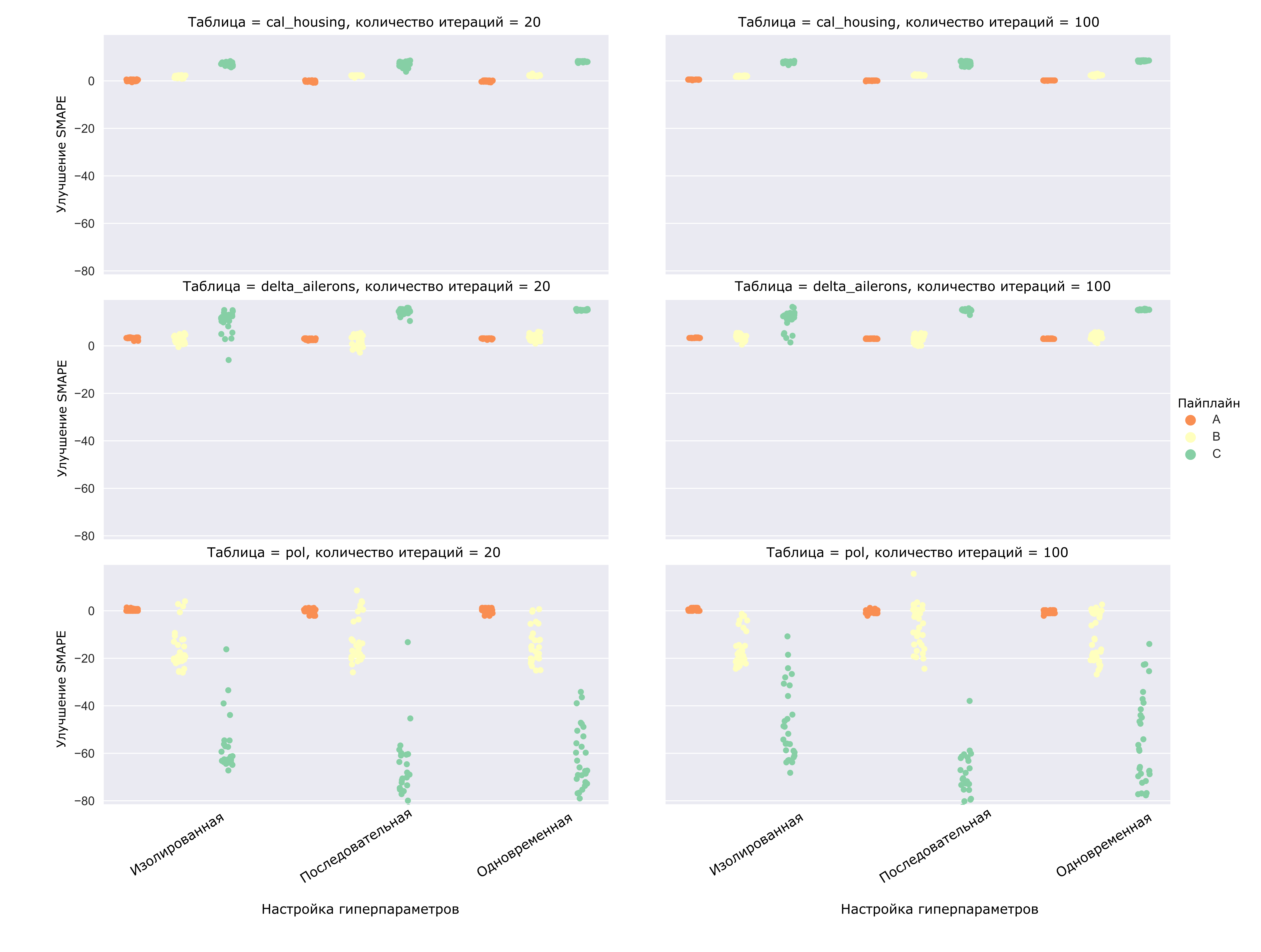
Рисунок 3. Улучшение метрики SMAPE при настройке гиперпараметров различными подходами, показанные на трёх регрессионных датасетах. Рассмотрены три варианта пайплайнов.
На рисунке каждое облако точек представляет собой выборку из тридцати запусков, то есть по тридцать запусков для каждого типа пайплайна (A, B, C), для каждого подхода (изолированный, последовательный, одновременный), для каждого датасета (три регрессионных) и для двух вариантов выделяемого количества итераций для оптимизации (20 и 100). Всего 1620 запусков модуля тюнинга для регрессии, и столько же для классификации.
Из общей картины сразу выбиваются результаты на датасете “pol”. Действительно, в подавляющем большинстве случаев настройка гиперпараметров приводила к ухудшению прогнозирования на отложенной выборке. Что ж, даже в случае, когда настройка гиперпараметров приводит в конечном итоге к увеличению ошибки прогноза все равно лучше выбрать такой алгоритм, который вредит меньше остальных.
Если же рассмотреть более “адекватные” запуски, видно, что в среднем одновременная настройка позволяет добиться более стабильно высокого результата: разброс значений меньше, а само облако располагается выше конкурентов.
Ещё одно наблюдение: в экспериментах используются пайплайны разной степени разветвленности, или сложности, по другому. Из Рисунка 3 видно, что как правило, чем сложнее пайплайн, тем больше пространство поиска для его настройки, и тем более существенный прирост метрики возможно получить.
На Рисунке 4 показаны результаты для классификационных датасетов.
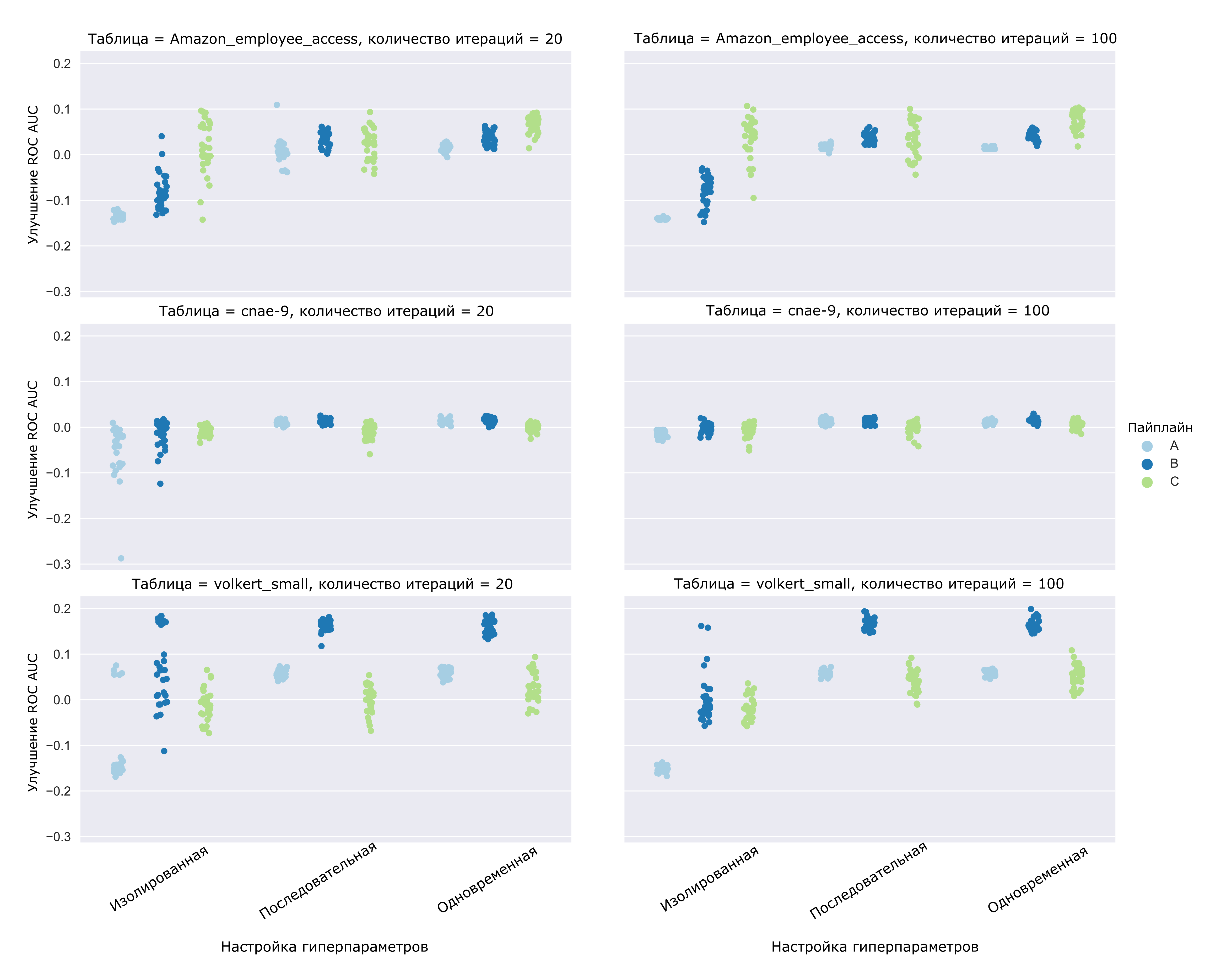
Рисунок 4. Улучшение метрики ROC AUC при настройке гиперпараметров различными подходами, показанные на трёх классификационных датасетах. Рассмотрены три варианта пайплайнов.
В общем, для классификации результаты такие же, как и для регрессии, вырисовывается победитель по приросту метрик и по разбросу таковых — одновременная настройка гиперпараметров.
Теперь рассмотрим более пристально некоторые случаи, а именно запуски по 20 итераций (Рисунок 5) для таблиц “Amazon_employee_access” (классификация) и “cal_housing” (регрессия).
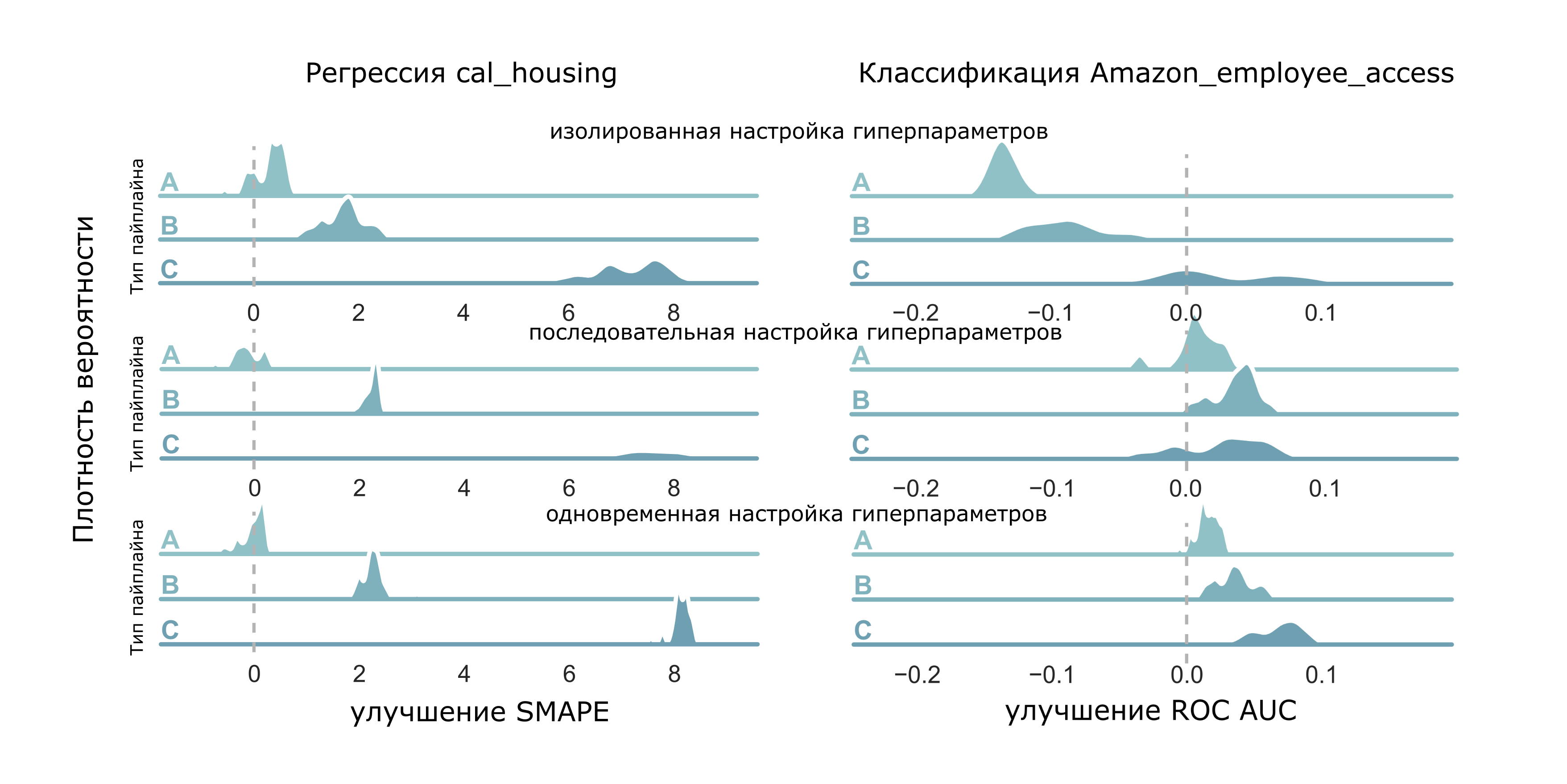
Рисунок 5. Ядерная оценка плотности улучшений метрик для рассматриваемых подходов на двух наборах данных.
Что же на рисунке видно? — Первое, заметно, что в случае с классификацией выборки улучшений метрики постепенно сползают “вправо” при движении в порядке изолированная настройка — последовательная настройка — одновременная. Это говорит о том, что одновременный подход позволяет лучше подбирать гиперпараметры, чем последовательный, а уже он, в свою очередь, надежней, чем изолированная настройка. Также видно, что только третий подход позволяет добиться стабильного улучшения метрики — при использовании других алгоритмов это не гарантировано.
Теперь рассмотрим распределения для пайплайна C при решении задачи регрессии: видно, что только в случае с одновременной настройкой выделяется один заметный высокий пик (мода) у распределения. В остальных двух случаях распределения либо не унимодальны (изолированная настройка), либо растянуты почти по всей оси абсцисс. То есть только в случае с одновременной настройкой удалось добиться высокой скученности результатов, что говорит о том, что если мы применим третий подход, то скорее всего получим такой же высокий результат, как и при прошлом запуске.
Теперь заценим время работы подходов на примере таблиц для регрессии на графике “violin plot” (Рисунок 6). На таком графике по бокам относительно центральной оси каждого элемента откладываются ядерные оценки плотности распределения. Таким образом места расширений у таких “скрипок” показывают моду выборки.
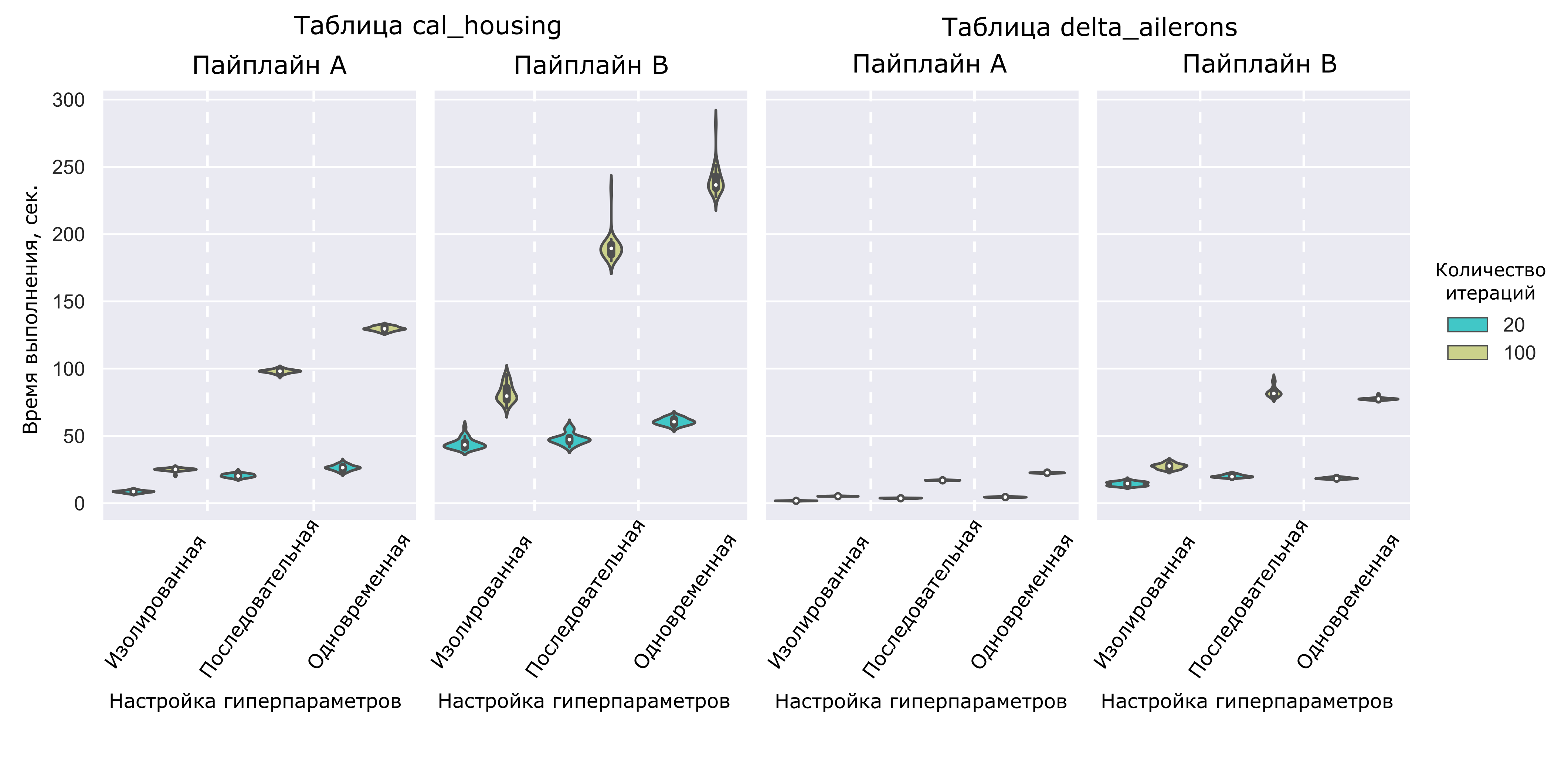
Рисунок 6. Время работы запусков модуля настройки гиперпараметров для некоторых пайплайнов при решении задачи регрессии.
Начнем с очевидного: чем больше итераций выделяется, тем дольше работает алгоритм. Теперь обратим внимание, что, как и предполагалось, изолированная настройка оказалась существенно более быстрым алгоритмом.
Однако заметим, что в случае последовательной настройки есть возможность для существенного улучшения. Все операции в пайплайне, которые в данную итерацию не обучаются с новыми гиперпараметрами и при этом не зависят от конфигурируемой модели (например, расположены в пайплайне перед таковой), можно не обучать, а просто вызывать метод predict у уже обученной модели. Действительно, ведь предикторы неизменны, гиперпараметры модели тоже не менялись — значит можно такую операцию поместить в кэш и доставать только для формирования прогноза. В случае с одновременной настройкой гиперпараметров возможности провести подобную модификацию нет.
Ну и раз мы дошли до финала, предлагаю подвести итог в виде сводной таблички с метриками (Таблица 2).
Таблица 2. Прирост метрики в процентах относительно исходной конфигурации. Показаны значения среднеквадратического отклонения. Не приводятся значения для регрессионного датасета “pol”. Полужирным начертанием показаны результаты лучшего подхода в каждом случае.
Русские Блоги
Практическое руководство по слиянию моделей машинного обучения
Автор: Тянь Янцзюнь
From:Datawhale
Аннотация: В этой статье вы узнаете, как выполнить слияние моделей для проектов интеллектуального анализа данных? Каковы общие методы слияния моделей? Какой метод выбрать для разных типов проблем?
Модельный фьюжн : Объединяя несколько разных моделей, можно повысить производительность машинного обучения. Этот метод широко используется в различных соревнованиях по машинному обучению, а также является ключом к спринту к вершине в критический момент соревнований. Модель слияния часто можно объединить с разных точек зрения, таких как результат модели, сама модель и набор образцов.
Данные и предыстория
https://tianchi.aliyun.com/competition/entrance/231784/information (Введение в интеллектуальный анализ данных на основе Али Тианчи)
Модельный фьюжн
Если вы планируете купить автомобиль, вы бы пошли прямо в первый магазин 4S и купили бы автомобиль непосредственно в рамках рекламной акции продавца? Вероятно, нет, вы сначала зайдете на веб-сайт, чтобы увидеть оценки других людей или сравнение различных моделей в различных измерениях некоторыми профессиональными учреждениями; вы также можете посоветоваться с друзьями и коллегами. Наконец, примите решение.
Слияние моделей использует ту же идею, то есть сочетание нескольких моделей может улучшить общую производительность. Ансамблевая модель — это мощный метод, который может повысить точность различных задач машинного обучения.
Слияние моделей — важное звено на более поздних этапах игры. Вообще говоря, существуют следующие типы:
1. Простая взвешенная сварка:
Регрессия (вероятность классификации): слияние среднего арифметического (среднее арифметическое), слияние среднего геометрического (среднее геометрическое);
Комплексный: усреднение рангов, объединение журналов.
Постройте многослойную модель и используйте результаты прогноза для соответствия прогнозу.
Метод продвижения с использованием нескольких деревьев использовался в xgboost, Adaboost и GBDT.
Усреднение
Основная идея : Для задач регрессии простой и понятный способ — взять среднее. Немного улучшенный метод — это средневзвешенное значение. Веса могут быть определены методом сортировки. Например, для трех основных моделей A, B и C эффекты модели ранжируются. Предполагая, что ранжирование равно 1, 2, 3, тогда веса, присвоенные трем моделям Это 3/6, 2/6, 1/6.
Метод среднего или средневзвешенного метода кажется простым, на самом деле, можно сказать, что более поздние усовершенствованные алгоритмы также основаны на этом.Установка пакетов или усиление — это идея объединения многих слабых классификаторов в сильные классификаторы.
Простой метод среднего арифметического: Метод усреднения усредняет результаты, предсказанные несколькими моделями. Этот метод можно использовать как для задач регрессии, так и для усреднения вероятностей задач классификации.
Метод средневзвешенного арифметического: Этот метод является продолжением метода средних значений. Учитывая, что возможности разных моделей различны и их вклад в конечный результат также различен, веса необходимы для характеристики важности разных моделей.
Голосование
Основная идея : Предположим, есть 3 базовые модели для задачи двоичной классификации.Теперь мы можем получить классификатор, получивший голосование, на основе этих базовых учащихся и использовать класс с наибольшим количеством голосов в качестве категории, которую мы хотим прогнозировать.
Метод голосования абсолютным большинством: Окончательный результат должен составлять более половины голосов.
Метод относительного большинства голосов: За окончательный результат проголосовало наибольшее количество голосов.
Метод взвешенного голосования: Принцип такой
Жесткое голосование : Голосуйте за несколько моделей напрямую, не различая относительной важности результатов модели.Класс с наибольшим количеством голосов — это класс, который окончательно предсказан.

Мягкое голосование: Добавлена функция установки весов, которая позволяет устанавливать разные веса для разных моделей, чтобы различать разную важность моделей.

Штабелирование
Основная идея
Стекинг заключается в использовании исходных данных обучения для изучения ряда базовых учащихся и использовании результатов прогнозов этих учащихся в качестве нового набора для обучения нового учащегося. Смоделируйте результаты, предсказанные разными моделями.

Метод, используемый при объединении отдельных учащихся, называется комбинированной стратегией. Для задач классификации мы можем использовать голосование, чтобы выбрать класс с наибольшим выходом. Для задач регрессии мы можем усреднить вывод классификатора.
Упомянутые выше метод голосования и метод усреднения являются очень эффективными стратегиями комбинирования. Другая стратегия комбинирования заключается в использовании другого алгоритма машинного обучения для комбинирования результатов отдельных машинного обучения. Этот метод называется стекированием.
В методе суммирования мы называем индивидуального учащегося первичным учащимся, учащийся, используемый для объединения, называется вторичным учащимся или метаузником, а данные, используемые вторичным учащимся для обучения, называются вторичным обучающим набором. Вторичный обучающий набор получается путем использования основного ученика в обучающем наборе.
Как укладывать

Процесс 1-3 предназначен для обучения отдельных учащихся, то есть учащихся начальной школы.
Процесс 5-9 заключается в использовании обученного отдельного учащегося для получения прогнозируемого результата, и этот прогнозируемый результат используется в качестве обучающей выборки для вторичного учащегося.
Процесс 11 состоит в том, чтобы обучить вторичного учащегося на основе результатов, предсказанных первичным учащимся, и получить модель, которую мы, наконец, обучили.
Подробный метод укладки
Модель стекирования — это, по сути, иерархическая структура. Для простоты анализируется только стекирование второго уровня. Предположим, у нас есть две базовые модели Model1_1, Model1_2 и вторичная модель Model2.
Step 1 Базовая модель Model1_1, обучается на обучающем наборе train, а затем используется для прогнозирования столбцов меток обучения и тестирования, которые представляют собой обучение модели P1, T1, Model1_1:

Обученная модель Model1_1 прогнозируется на тренировке и тесте соответственно, а прогнозируемые метки — P1 и T1 соответственно.

Step 2. Базовая модель Model1_2 обучается на обучающей выборке train, а затем используется для прогнозирования столбцов меток обучающей и тестовой, которые являются P2, T2, model1_2 обучением модели:

Обученная модель Model1_2 прогнозируется на тренировке и тестировании соответственно, а прогнозируемые метки равны P2 и T2 соответственно.

Step 3. Объедините P1, P2 и T1, T2 соответственно, чтобы получить новый обучающий набор и набор тестов train2, test2.

Затем используйте вторичную модель Model2 для обучения с реальной меткой обучающего набора в качестве метки, обучения с помощью train2 в качестве функции, прогнозирования test2 и получения столбца прогнозируемых меток окончательного набора тестов.

Это основная оригинальная идея нашей двухслойной укладки. На основе результатов прогнозирования различных моделей добавляется и повторно обучается еще один уровень модели, чтобы получить окончательный прогноз модели.
Стекинг — это, по сути, такая простая идея, но иногда возникает проблема, если распределение обучающего набора и тестового набора не так согласовано. Проблема состоит в том, чтобы использовать теги, обученные исходной моделью, а затем использовать настоящие теги для повторного обучения Несомненно, это приведет к тому, что определенная модель будет переобучаться обучающей выборке, поэтому, возможно, способность к обобщению или влияние модели на набор тестов будет в определенной степени снижена, поэтому теперь проблема заключается в том, как уменьшить переобучение при переподготовке, Здесь обычно есть два метода:
Попробуйте выбрать простую линейную модель для вторичной модели.
Используйте K-кратную перекрестную проверку


Смешивание
Основная идея: Смешивание использует тот же метод, что и наложение, но только выбирает результат свертки из обучающего набора, а затем конкатируется с исходной функцией в качестве функции метаученика метаученика и выполняет ту же операцию с набором тестов.
Разделите исходный обучающий набор на две части, например, 70% данных как новый обучающий набор, а оставшиеся 30% как тестовый набор.
На первом уровне мы обучаем несколько моделей на этих 70% данных, а затем предсказываем метку 30% данных, а также предсказываем метку тестового набора.
На втором уровне мы напрямую используем 30% данных, предсказанных в первом слое, в качестве новой функции для продолжения обучения, затем используем метку, предсказанную первым слоем тестового набора, как функцию, и используем модель, обученную во втором. слой, чтобы делать дальнейшие прогнозы.
Смешивание тренировочного процесса:
Весь обучающий набор разделен на две части: обучающие наборы и проверочные наборы;
Обучить модель на обучающих наборах;
Получать результаты прогнозов на проверочных и тестовых наборах;
Использовать оригинальные функции наборов проверки и результаты прогнозирования различных базовых моделей в качестве входных данных для нового метаученика метаученика для обучения;
Используйте обученную модель метаученика, чтобы прогнозировать наборы тестов и результаты прогнозирования на базовой модели, чтобы получить окончательный результат.
Сравнение укладки и смешивания:
Смешивание проще, чем наложение, потому что нет необходимости выполнять k раз перекрестной проверки, чтобы получить функцию укладчика.
Смешивание позволяет избежать проблемы утечки информации: генераторы и укладчики используют разные наборы данных
К недостаткам можно отнести:
blending Используется очень мало данных (второй этап блендера использует только 10% обучающего набора)
Блендер может переоснастить
Стекирование с использованием множественной перекрестной проверки будет более надежным
Bagging
Основная идея: В основе баггинга лежит бутстрап (самовыборка), то есть выборка с заменой. Размер обучающего подмножества такой же, как размер исходного набора данных. Технология Bagging использует подмножества, чтобы понять распределение всего набора образцов, и размер подмножества, отобранного с помощью упаковки, меньше, чем исходный набор.
Метод начальной загрузки используется для генерации большого количества подмножеств на основе исходного набора данных.
Обучите базовую модель слабой модели на основе этих подмножеств
Модели обучаются параллельно и независимо друг от друга
Окончательный результат прогноза зависит от результатов прогноза нескольких моделей.
Бэггинг — это метод параллельного ансамблевого обучения, то есть обучение базового учащегося можно проводить одновременно без какой-либо последовательности. Бэггинг использует метод «замещающей выборки» для выбора обучающего набора. Для обучающего набора, содержащего m выборок , Существуют операции случайной выборки с заменой m раз, так что получается выборка из m выборок, так что около 36,8% выборок в обучающей выборке не собираются. Повторяя таким же образом, мы можем собрать T наборов данных, содержащих m выборок, тем самым обучить T базовых учеников и, наконец, объединить результаты этих T базовых учеников.
Схема алгоритма:

Boosting
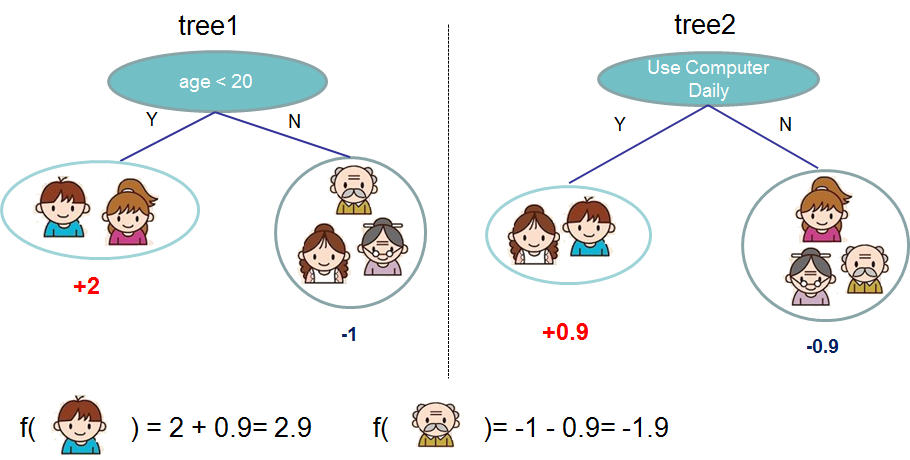
Основная идея: Повышение — это последовательный рабочий механизм, то есть обучение отдельных учащихся зависит от него и должно быть последовательно преобразовано в последовательную форму. Повышение — это процесс сериализации, и последующие модели исправят результаты прогнозов предыдущих моделей. Другими словами, более поздняя модель зависит от предыдущей модели.
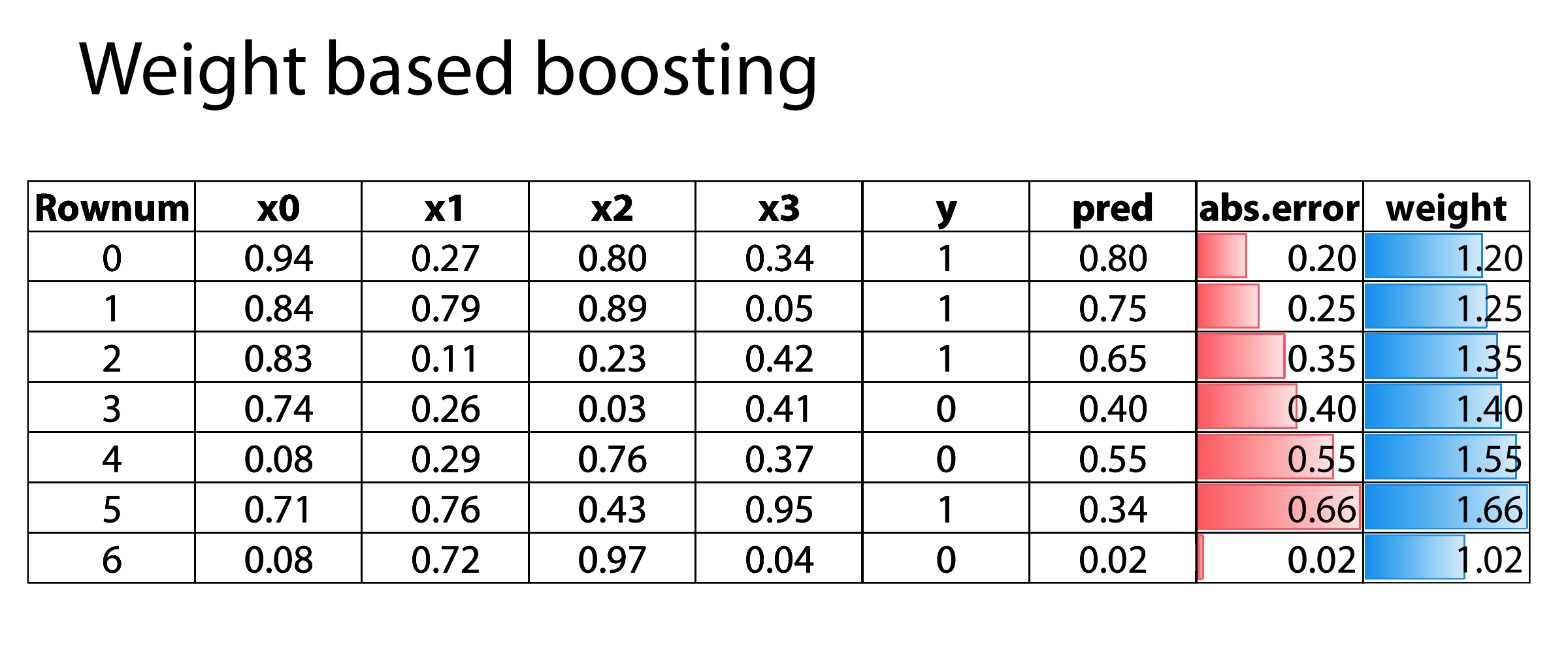
Основная идея состоит в том, чтобы увеличить вес выборки ошибок, предсказанной предыдущим базовым учащимся в процессе обучения, чтобы последующий базовый учащийся уделял больше внимания этим неправильно помеченным обучающим выборкам, исправлял эти ошибки в максимально возможной степени и сериализовал их. до тех пор, пока они не будут сгенерированы.Требуемые базовые T-учащиеся, Boosting окончательно взвесили и объединили этих T-учащихся для создания комитета учащихся.
Вот двухстраничный РРТ профессора Алекса Илера из Калифорнийского университета в Ирвине:


Ускорение тренировочного процесса:
Создайте подмножество на основе исходного набора данных
Первоначально всем точкам данных присвоен одинаковый вес.
Создайте базовую модель на основе этого подмножества
Используйте эту модель для прогнозирования всего набора данных.
Вычислить ошибку на основе истинного значения и прогнозируемого значения
Наблюдения, которые предсказаны неправильно, будут иметь больший вес.
Затем создайте модель для прогнозирования на основе ошибки предыдущего прогноза, эта модель попытается исправить предыдущую модель.
Аналогичным образом постройте несколько моделей, каждая из которых исправит предыдущие ошибки.
Окончательная модель (сильный ученик) представляет собой взвешенное сочетание всех слабых учеников.
Источник https://nagornyy.me/it/postroenie-ansamblei-modelei/
Источник https://habr.com/ru/post/672486/
Источник https://russianblogs.com/article/58841477054/





