Выявление инцидентов ИБ с помощью SIEM: типичные и нестандартные задачи, 2020
В инфраструктуре компаний происходит много событий, которые могут свидетельствовать о различных инцидентах информационной безопасности, таких как нарушение политик пользователями или проникновение злоумышленника в локальную сеть. Для централизованного сбора и анализа информации о событиях используют решения класса security information and event management (SIEM). Основная задача SIEM-системы — не просто собрать информацию о событиях с различных источников — сетевых устройств, приложений, журналов ОС, средств защиты, — но и автоматизировать процесс обнаружения инцидентов, а также своевременно информировать о них специалистов по безопасности. Пилотный проект позволяет продемонстрировать работу SIEM-системы в условиях, приближенных к условиям реальной корпоративной инфраструктуры. После таких проектов мы получаем много ценной информации от экспертов, поработавших с системой, и эта обратная связь позволяет совершенствовать продукт.
В этой статье мы расскажем о результатах 23 пилотных проектов по внедрению системы MaxPatrol SIEM, проведенных во второй половине 2019 — начале 2020 года 1 , и на их примере покажем, как информация из различных источников при использовании SIEM-системы позволяет выявлять инциденты ИБ в компании. Кроме того, расскажем о решении нетипичных задач с помощью SIEM-системы.
124 дня средняя длительность пилотного проекта
Рисунок 1. Портрет участников исследования
Как начать выявлять инциденты ИБ с помощью SIEM-системы
Для того чтобы начать выявлять инциденты ИБ в инфраструктуре компании с помощью SIEM-системы, необходимо сначала тщательно подготовиться:
- Сформулировать задачи, которые вы планируете решать с помощью SIEMсистемы. Следует учитывать особенности инфраструктуры, положения корпоративной политики ИБ, а также требования и рекомендации регулирующих организаций.
- Определить список источников, которые необходимо подключить к SIEMсистеме для решения поставленных задач.
- Если вы готовитесь к пилотному внедрению, то следует определить четкие границы пилотной зоны. Фрагмент инфраструктуры, попадающий под пилотное внедрение, должен позволить оценить работу SIEM-системы и решить поставленные задачи.
Рассмотрим подробнее, какие задачи решались с помощью SIEM-системы в ходе пилотных проектов, и разберем, какие источники следует подключать для выявления различных типов инцидентов. Также приведем примеры реальных инцидентов и кибератак, выявленных в ходе проведенных работ.
Задачи для SIEM-системы: типичные и нестандартные
SIEM-система традиционно применяется для решения проблемы накопления и оперативной обработки данных о событиях безопасности, поэтому первоочередные задачи, решаемые в рамках каждого пилотного проекта, — это сбор, хранение и обработка событий ИБ. Однако область применения SIEM-решения этим не ограничивается: с помощью SIEM-систем решаются такие важные задачи, как выявление и расследование инцидентов ИБ, инвентаризация активов, контроль защищенности информационных ресурсов. Как правило, список задач для пилотного проекта определяется на основании целей дальнейшего использования SIEM-системы в компании.
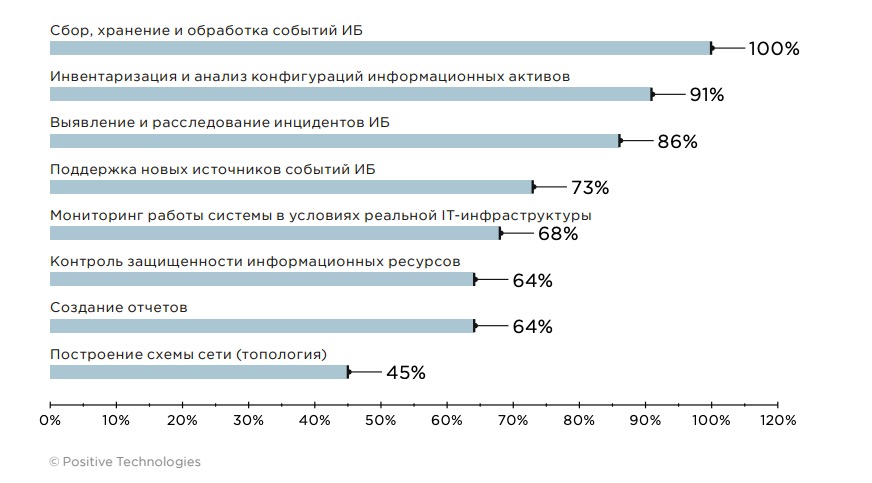
Рисунок 2. Список популярных задач для пилотного внедрения MaxPatrol SIEM (доля проектов)
Мы всегда рекомендуем формулировать такие задачи для пилотного проекта, которые важны для компании и учитывают особенности ее инфраструктуры, а также учитывают требования нормативной документации, а не такие, которые просто покажут, что SIEM-система включена и работает. Это позволяет оценить функциональность системы, проверить корректность ее конфигурации, а также определить, какие источники событий необходимо подключить для решения поставленных задач, убедиться в отсутствии «слепых зон».
В одной из компаний SIEM-система была настроена на выявление несанкционированного появления активов внутри сети, когда служба ИТ без согласования со службой ИБ вводила какие-либо новые информационные объекты. Благодаря встроенной функции инвентаризации сети появилась возможность в реальном времени детектировать события в контурах разработки и стандартизировать процесс DevOps.

Рисунок 3. Примеры нестандартных задач, решенных в рамках пилотного внедрения SIEM-системы
Источники для сбора событий
Поиск инцидентов начинается с подключения источников, которые генерируют разнородные события. Для получения наиболее полного представления о том, что происходит в инфраструктуре компании, рекомендуется подключать все имеющиеся источники IT-событий и событий ИБ.
IT-источники — общесистемное прикладное программное и аппаратное обеспечение, порождающее IT-события. IT-источники сообщают о тех или иных явлениях в автоматизированной системе без оценки уровня их защищенности (без оценки — «хорошо» или «плохо»). Примеры: журналы серверов и рабочих станций (для контроля доступа, обеспечения непрерывности, соблюдения политик информационной безопасности), сетевое оборудование (контроль изменений конфигураций и доступа к устройствам).
Источники событий ИБ — специализированное программное и аппаратное обеспечение для информационной безопасности, порождающее события ИБ. Такие источники обладают дополнительными внешними знаниями о том, как трактовать те или иные события с точки зрения безопасности (является ли наблюдаемое явление «хорошим» или «плохим»). Примеры источников событий ИБ: IDS/IPS (для сбора данных о сетевых атаках), средства антивирусной защиты (обнаружение вредоносных программ).
В рамках пилотных проектов внедрение SIEM-системы производится на тестовую площадку, имитирующую фрагмент реальной инфраструктуры компании, либо в выделенную пилотную зону, включающую в себя ряд источников.
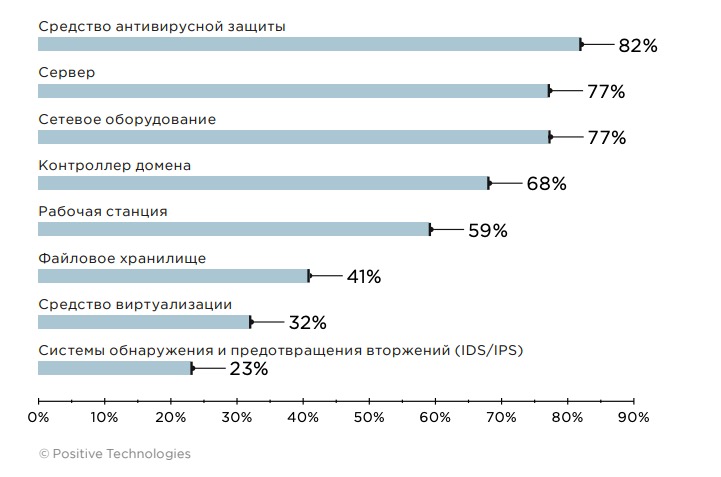
Рисунок 4. Наиболее часто подключаемые источники событий (доля проектов)
Для сбора наиболее полных данных со всех источников SIEM-система должна уметь взаимодействовать с широким спектром сетевых протоколов и технологий сетевого взаимодействия: syslog, WMI, RPC, Telnet, SSH, ODBC и другими. Например, для получения сообщений из системных журналов и журналов безопасности Windows (WinEventLog, WindowsAudit) на серверах и рабочих станциях используется протокол syslog. Так в SIEM-систему попадает информация о событиях, определенных политиками аудита Windows (таких как вход в систему, доступ к объектам, изменение привилегий). WMI позволяет собирать информацию с Windows-устройств о таких событиях, как создание, изменение или удаление файлов с определенным расширением; подключение физических устройств; запуск служб в ОС. Также рекомендуется дополнительно использовать инструмент расширенного аудита — Sysmon, поскольку в журналы аудита безопасности Windows попадает не вся информация. Sysmon отслеживает изменения в ветках реестра, видит, когда злоумышленник пытается получить хеш-значения паролей пользователей, а также позволяет отследить вредоносную активность внутри сети, получить информацию об источнике, включая хеш-значение файла, породившего процесс.
Не все инциденты можно выявить, основываясь на данных, полученных с серверов и рабочих станций. Для обнаружения атак в сетевом трафике (например, при использовании злоумышленником туннелей для передачи вредоносного кода или атаки DCSync) рекомендуется дополнить решение класса SIEM системой анализа сетевого трафика (NTA/NDR).
Ниже представлен список основных событий ИБ, выявляемых с помощью SIEM-системы, и соответствующих им источников.
- Прокси-серверы с контролем контента
- Средства защиты веб-трафика
- Средства защиты почты
- Средства защиты конечных узлов со встроенными модулями контроля веб-ресурсов и электронной почты
- Межсетевые экраны
- Средства обнаружения и предотвращения вторжений
- Межсетевые экраны
- Системы обнаружения и предотвращения вторжений
- Системы выявления и блокировки сетевых DoS-атак
- Средства обнаружения и предотвращения вторжений
- Средства обнаружения и предотвращея вторжений
- Сканеры уязвимостей и средства аудита
- Антивирусные средства защиты
- Антивирусные средства защиты
- Средства обнаружения и предотвращения вторжений
- Сканеры уязвимостей
- Системы предотвращения утечек данных
- Межсетевые экраны нового поколения (NGFW)
- Системы предотвращения течек данных
- Системы класса User and Entity Behavior Analytics
Выявленные инциденты ИБ
В рамках пилотных проектов для демонстрации возможностей SIEM-системы часто выполняется моделирование условий, которые приводят к регистрации киберинцидента. Однако, помимо смоделированных, в 100% проектов, вошедших в выборку, MaxPatrol SIEM зафиксировал еще и реальные инциденты ИБ. Во время пилотных проектов были выявлены события ИБ, свидетельствующие о потенциальных кибератаках, заражении вредоносным ПО, нарушении политик ИБ, а также об отклонениях в поведении пользователей.
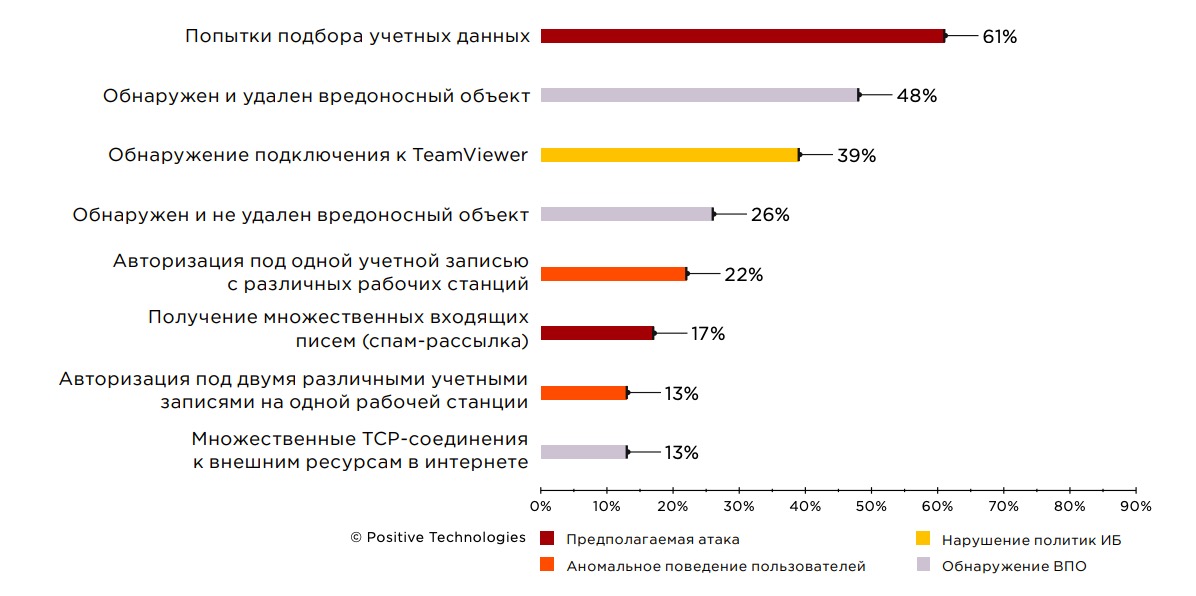
Рисунок 5. Наиболее часто выявляемые инциденты ИБ (доля проектов)
Предполагаемая атака
Специалисты Positive Technologies в ходе работ по тестированию на проникновение часто выявляют в инфраструктуре заказчика следы кибератак. Это говорит о том, что либо атака осталась незамеченной специалистами по ИБ, либо при расследовании инцидента не удалось выявить все скомпрометированные узлы, а значит, и полностью устранить последствия. Причиной может быть как отсутствие современных технических средств для выявления атак, так и недостаточный объем данных, собираемых с источников событий, и следовательно, невозможность детально отслеживать все происходящие события в инфраструктуре компании.
Во время пилотных проектов были выявлены события, которые свидетельствуют о потенциальных атаках. Многие из этих событий связаны, в частности, с получением злоумышленниками информации о скомпрометированной системе и внутренней сети: после проникновения во внутреннюю сеть жертвы преступникам требуется определить, где в инфраструктуре они находятся, принять решение о дальнейших действиях, получить учетные данные пользователей для подключения к серверам и рабочим станциям. Своевременное обнаружение этих событий может помочь специалистам по ИБ остановить кибератаку на ранней стадии и минимизировать ущерб.
К примеру, в одном из пилотных проектов был обнаружен запрос сеансового билета Kerberos для несуществующего пользователя. Подобные события могут свидетельствовать об ошибочной настройке сервиса (например, учетная запись для запуска службы была удалена, но сама служба продолжает работать) или о попытке перечисления существующих пользователей.
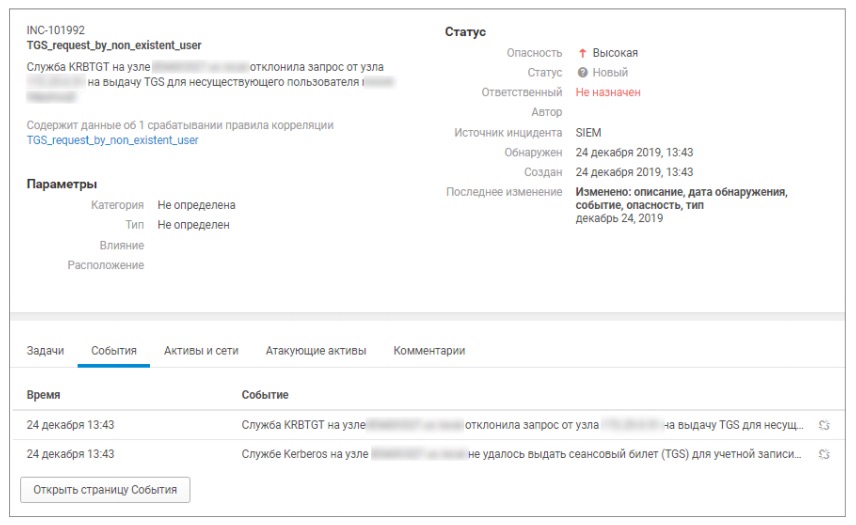
Рисунок 6. Инцидент «Обнаружение сеансового билета Kerberos для несуществующего пользователя»
В ходе атак на контроллер домена, в котором используется аутентификация по протоколу Kerberos, злоумышленники могут прибегнуть к атаке Kerberoasting. Любой аутентифицированный в домене пользователь может запросить Kerberos-билет для доступа к сервису (Ticket Granting Service, TGS). Билет TGS зашифрован NT-хешем пароля учетной записи, от имени которой запущен целевой сервис. Злоумышленник, получив значение TGS-REP, может его расшифровать, подобрав пароль от ассоциированной с сервисом учетной записи, который зачастую является простым или словарным. В ходе пилотных проектов в ряде компаний были выявлены подобные атаки.
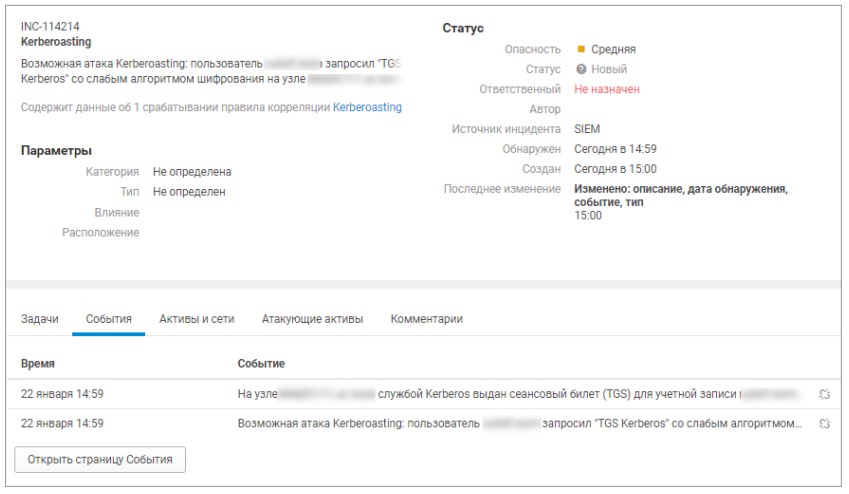
Рисунок 7. Инцидент «Атака Kerberoasting»
Перечисление существующих пользователей через запрос сеансового билета Kerberos, а также Kerberoasting злоумышленники применяют в атаках с использованием тактик «Разведка» (Discovery) и «Получение учетных данных» (Credential Access) по модели MITRE ATT&CK. SIEM-система, обладающая правилами детектирования популярных техник атак, сумеет обнаружить активность злоумышленников еще во время их попыток получить список учетных записей домена и перечень установленных приложений и служб.
В одной компании была выявлена активность злоумышленника, преодолевшего сетевой периметр с помощью фишингового письма. Вредоносное ПО начало собирать информацию о сети. SIEM-система зафиксировала, что на активе пользовательской группы (бухгалтерия) выполняются административные команды, связанные со сбором информации о домене. Таким образом с помощью SIEM-системы был выявлен факт компрометации с использованием фишинга, который пропустило другое средство защиты.
SIEM-система помогает в выявлении и других типов атак. Так, во время проведения одного из пилотных проектов была своевременно обнаружена DDoS-атака. После анализа внешних адресов, с которых обращались злоумышленники, эти адреса были заблокированы на корпоративном межсетевом экране.

Рисунок 8. Выявление DDoS-атаки с помощью MaxPatrol SIEM
В ряде пилотных проектов выполнялся ретроспективный анализ событий ИБ для выявления атак и фактов компрометации объектов инфраструктуры компании, пропущенных или неверно приоритизированных при реализации штатных мер защиты. Так, например, удалось выявить и пресечь целенаправленную атаку на ресурсы одной компании, которая длилась не менее 8 лет. По результатам анализа журналов регистрации событий SIEM-системы были выявлены следы действий злоумышленников на 195 узлах контролируемой инфраструктуры. Причем, как выяснилось во время расследования, преступники были активны на протяжении всех этих лет, а именно использовали вредоносное ПО:
- для связи с командным сервером,
- удаленного исполнения команд,
- исследования скомпрометированной инфраструктуры,
- извлечения учетных данных пользователей на узлах,
- сжатия данных в архивы,
- передачи файлов на командный сервер и приема с него.
В минимальные сроки были заблокированы командные серверы злоумышленников и ликвидировано их присутствие в инфраструктуре. В ходе расследования специалисты Positive Technologies установили принадлежность атакующих к группировке TaskMasters.
Обнаружение вредоносного ПО
Каждый пятый инцидент, выявляемый в ходе пилотных проектов, связан с обнаружением вредоносного ПО. Причем большинство из них (порядка 85%) связаны с фишинговыми рассылками. Согласно нашему исследованию APT-группировок, атаковавших компании по всему миру, 90% группировок начинают атаки именно с целенаправленных фишинговых рассылок по электронной почте.
В одном из пилотных проектов было зафиксировано большое количество вредоносных писем, в частности содержащих Trojan-Banker.RTM, отправленных сотрудникам компании с 592 различных IP-адресов. Операторов этого вредоносного ПО в основном интересуют корпоративные банковские счета, поэтому фишинговые письма адресуют бухгалтерам и финансистам, имитируя переписку с финансовыми структурами. Темой такого письма может быть, например, «Заявка на возврат», «Пакет документов за прошлый месяц» или «Паспортные данные сотрудников».
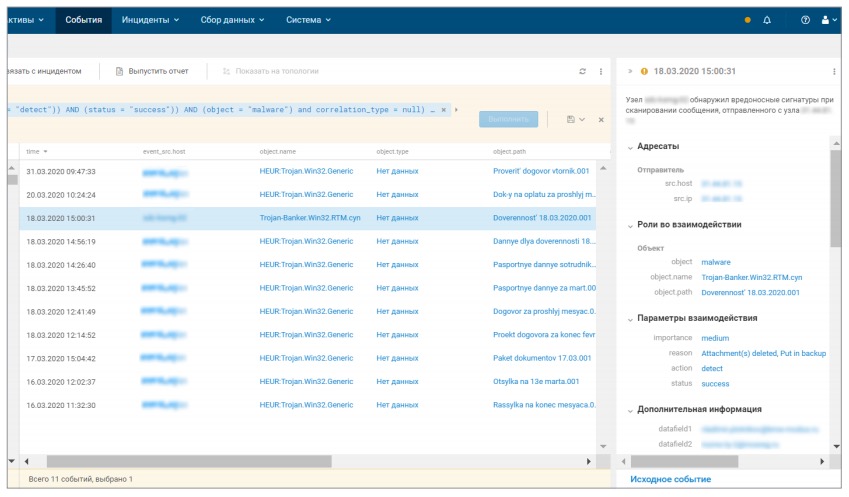
Рисунок 9. Выявление фишинговых рассылок с помощью MaxPatrol SIEM
Аномальное поведение пользователей
В исследовании, посвященном результатам работ по внутреннему тестированию на проникновение, мы говорили, что методы атак во внутренней сети основаны не только на эксплуатации уязвимостей ПО, но и на использовании архитектурных особенностей ОС и механизмов аутентификации, а также на выполнении легитимных действий, предусмотренных функциональностью системы. Легитимные действия, которые позволяют развить вектор атаки, составляют почти половину от всех действий пентестеров. Такие действия иногда сложно отличить от повседневной деятельности пользователей или администраторов, но они могут указывать на скрытое присутствие злоумышленников. Поэтому аномалии в поведении пользователей должны служить поводом для более подробного изучения событий. Примеры событий, на которые стоит обратить внимание сотрудникам службы ИБ, — это попытки выгрузки списков локальных групп или пользователей, создание нового аккаунта сразу после авторизации. В нескольких пилотных проектах SIEM-система фиксировала использование одной учетной записи на нескольких рабочих станциях, что могло означать компрометацию учетных данных. Еще одним признаком потенциальной компрометации учетных данных является работа сотрудника в ночное время.

Рисунок 10. Пример инцидента «Работа в ночное время»
Нарушение политик ИБ
Еще одна категория инцидентов — это нарушения политик ИБ. Речь идет о выявлении фактов несоответствия требованиям нормативных документов, таких как PCI DSS, приказ ФСТЭК № 21, а также корпоративным политикам ИБ. Правила, устанавливаемые этими документами, направлены на обеспечение приемлемого уровня защищенности компании. Однако пользователи не всегда строго соблюдают все требования. В половине компаний в ходе пилотных проектов были выявлены нарушения политик ИБ. Так, например, в 39% пилотных проектов были зафиксированы случаи работы программ для удаленного управления компьютером. Эти события могут быть легитимными, например когда инженер технической поддержки удаленно подключается для настройки сервера, а могут указывать на получение доступа злоумышленниками (техника атаки Remote Access Software). Как правило, компаниям рекомендуется ограничить список узлов, на которых может использоваться ПО для удаленного доступа.
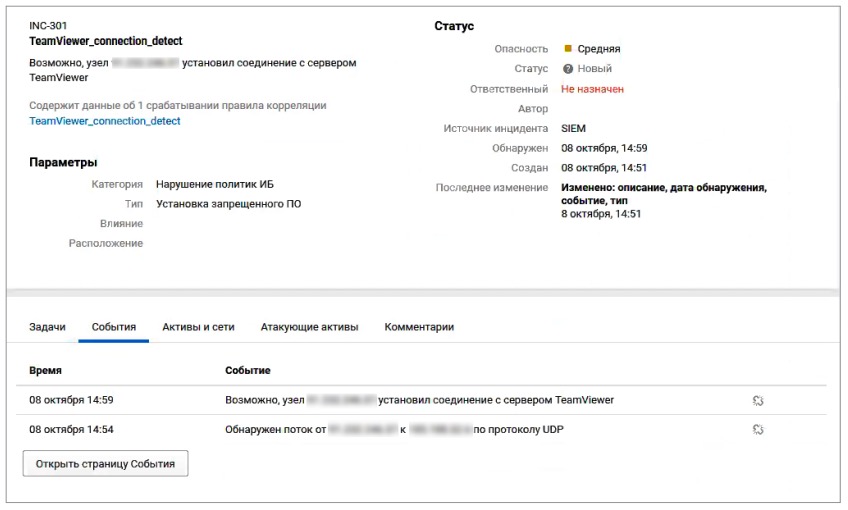
Рисунок 11. Инцидент «Выявление работы TeamViewer»
SIEM-система может применяться для проверки выполнения организационных распоряжений в части ИБ. Так, в одной из компаний было необходимо отказаться от определенного ПО, и с помощью SIEM-системы удалось собрать информацию о его использовании. Другой пример — использование решения класса SIEM в ряде организаций для проверки выполнения предписаний по смене паролей.
Заключение
Во всех компаниях происходят инциденты ИБ: выявляются использование вредоносного ПО, события, которые могут свидетельствовать о кибератаке или нарушении политик ИБ. Работы по тестированию на проникновение, выполняемые экспертами Positive Technologies, подтверждают, что в компаниях нередко выявляются следы более ранних атак хакеров, которые не были вовремя замечены службой ИБ. Для обнаружения атак на ранней стадии необходимо знать обо всем, что происходит в инфраструктуре компании. Для этого нужно собирать как можно больше информации о событиях, ведь чем полнее ведется сбор событий и чем больше источников подключено, тем больше шансов своевременно выявить подозрительную активность, принять меры по пресечению атаки и минимизировать негативные последствия.
Большой объем регистрируемых данных требует автоматизированной обработки с помощью таких решений, как SIEM. SIEM-система использует корреляцию, чтобы связывать вместе собранные данные, выявлять шаблоны, указывающие на инцидент. Опыт специалистов экспертного центра безопасности Positive Technologies показывает, что правила корреляции дают отправную точку для обнаружения большинства кибератак 2 , в том числе сложных многоступенчатых APT-атак, а также служат основой для расследования инцидентов. Если дополнительно используется система глубокого анализа трафика (решения класса NTA/NDR), то это позволяет отследить подозрительную активность не только на узлах, но и в сетевом трафике. Стоит принять во внимание, что к расследованию инцидентов следует привлекать квалифицированных экспертов, которые сумеют полностью восстановить цепочку атаки.
Не прервать связующий процесс, или Еще раз о непрерывности бизнеса и о роли управления инцидентами
Не прервать связующий процесс, или Еще раз о непрерывности бизнеса и о роли управления инцидентами
Не прервать связующий процесс, или Еще раз о непрерывности бизнеса и о роли управления инцидентами
Ежедневно в компаниях происходит множество инцидентов, приводящих к нарушению непрерывности их деятельности. Имея разный характер и последствия для бизнеса, они так или иначе приводят к прямым или косвенным финансовым потерям.

Дмитрий Моисеев
Cissp Руководитель практики систем мониторинга
событий и управления инцидентами ИБ (SIEM),
“Астерос Информационная безопасность»
Немного статистики Как показывает статистика, в среднем около 30% всех происходящих инцидентов ИБ влекут за собой либо временную недоступность критичных данных, либо прерывание бизнес-процессов компании на средний срок, и около 10% – на длительный срок. Здесь следует уточнить, что понятие «среднего» или «длительного» срока всегда индивидуально. К примеру, для банков под «средним» сроком, как правило, понимают простой около 5–6 часов, под «длительным» – прерывание критичного бизнес-процесса до нескольких дней. Если перевести в цифры, то опять же простой деятельности крупного банка в течение 1 ч (в будни) может стоить несколько сотен тысяч долларов, а сутки – несколько миллионов, простой же в течение недели, как правило, приводит к банкротству банка.
15 ноября 2013 г. в работе сотовой сети «Билайн» на севере Москвы произошел сбой. Компания сразу проинформировала абонентов о ситуации в своем Facebook и на официальном сайте. Объясняя причину неполадки, лишившей часть москвичей связи, оператор рассказал, что накануне ночью специалистами Ericsson и «Билайн» проводились плановые работы по модернизации сети, в ходе которых была выявлена некорректная работа ПО, поэтому некоторые абоненты испытывали проблемы со связью.
Среди частых причин подобных инцидентов – сбои и отказы IT и телекоммуникационной инфраструктуры, ошибки персонала, перебои электропитания и др., немалая доля приходится на инциденты информационной безопасности, приводящие к нарушению доступности IT-ресурсов или информации, необходимой для выполнения того или иного бизнес-процесса компании.
Обеспечение непрерывности бизнеса организации должно являться одной из приоритетных задач для руководства компании. Грамотное выстраивание данных процессов позволит снизить вероятность нарушений деятельности, а также минимизировать ущерб от инцидентов за счет их активного выявления и снижения времени реагирования на них.
ISO вам в помощь
Как это реализуется на практике? Международный стандарт ISO/IEC 27001 четко указывает на то, что управление непрерывностью бизнеса является одной из основных областей контроля и необходимой составляющей любой системы менеджмента ИБ. Несмотря на то что обеспечение непрерывности бизнеса выходит далеко за рамки вопросов информационной безопасности (ИБ является для них лишь одной из составляющих) и тесно связано со всеми бизнес-подразделениями компании, выстраивать соответствующие процессы в организациях часто приходится именно специалистам по ИБ.
Международный стандарт ISO 22301 описывает модель PDCA применительно к выстраиванию системы управления непрерывностью бизнеса (см. рис. 1).

Для того чтобы выстроить эффективные процессы обеспечения непрерывности бизнеса, необходимо выделить следующие основные этапы планирования непрерывности бизнеса:
- инициация проекта (получение поддержки со стороны руководства, планирование и выделение ресурсов, назначение ответственного и т.п.);
- разработка политики обеспечения непрерывности бизнеса;
- анализ деятельности компании и выявление критичных бизнес-процессов;
- разработка стратегии обеспечения непрерывности бизнеса и его восстановления;
- разработка планов обеспечения непрерывности бизнеса и восстановления IT;
- обучение персонала и проведение регулярных учений;
- регулярное тестирование планов обеспечения непрерывности бизнеса и планов восстановления IT;
- непрерывное совершенствование системы обеспечения непрерывности бизнеса.
Подходов к выстраиванию процессов обеспечения непрерывности бизнеса достаточно много, это и международные стандарты BS 25999, ISO 22301, и ведущие мировые рекомендации BCI Good Practice Guidelines. Но я бы хотел остановиться на роли процессов управления инцидентами ИБ в общей системе обеспечения непрерывности бизнеса компании, поразмышлять над тем, почему так важно их правильно интегрировать с процессами ОНБ и постоянно повышать их эффективность.
Типичный процесс реагирования на нештатные ситуации делится на следующие основные этапы:
- экстренные действия в случае чрезвычайной ситуации (Emergency Response) – то есть немедленные действия, которые необходимо предпринять в случае наступления чрезвычайной ситуации, еще до момента ее более глубокого анализа, например связь с экстренными службами, эвакуация персонала и т.п.;
- управление инцидентами (Incident Management) – ответные действия в случае обнаружения инцидента (категорирование инцидента, анализ последствий, оповещение об инциденте, эскалация информации для его обработки и т.п.);
- обеспечение непрерывности деятельности (Business continuity) – действия по обеспечению выполнения затронутых инцидентом бизнес-процессов на приемлемом уровне (минимально необходимом);
- восстановление деятельности (Recovery) – восстановление бизнес-процессов и поддерживающей их IT-инфраструктуры до нормального уровня функционирования.
Безусловно, важны все указанные этапы, однако от эффективности выполнения процессов управления инцидентами напрямую зависит масштаб ущерба от инцидентов и возможность соблюдения требований бизнеса к его восстановлению. Почему?
Управляя инцидентами – управляешь непрерывностью
В рамках разработки планов обеспечения непрерывности бизнеса и планов восстановления IT для каждого критичного бизнес-процесса и поддерживающей его IT-инфраструктуры необходимо оценивать и затем утверждать параметры восстановления – Recovery Time Objective (RTO) и Recovery Point Objective (RPO), которые должны соблюдаться и соответствовать требованиям бизнеса.
Несоблюдение этих параметров восстановления может привести к росту ущерба и сведению на нет всех усилий по управлению непрерывностью бизнеса. В связи с этим крайне важным действием является своевременная идентификация инцидента (или критичного события), который может привести к возникновению нештатной ситуации и, следовательно, нарушению выполнения критичного бизнес-процесса. Здесь важно уметь быстро проанализировать обстановку и все события, связанные с данным инцидентом, чтобы классифицировать его и выбрать план обработки.
Для такого уровня оперативности действий необходимо иметь обученный персонал, выстроенные и задокументированные процессы управления инцидентами и планы коммуникаций «на случай, если». Кроме того, в арсенале должны быть все необходимые инструментальные средства для анализа обстановки и сбора необходимой актуальной информации.
Самый SOC
Инциденты ИБ играют заметную роль во всем спектре проблем, способных привести к нарушениям операционной, производственной, управленческой деятельности. По результатам исследования Horizon Scan 2012, проведенного организацией the Business Continuity Institute (BCI) в 2012 г., наиболее актуальными угрозами для большинства компаний являются:
- сбои и отказы IT и телекоммуникационной инфраструктуры;
- утечка конфиденциальной информации;
- кибератаки (вредоносное ПО, DDoS и т.п.).
При этом угрозы ИБ наиболее актуальны для компаний финансовой сферы, телекома, здравоохранения и энергетики.
Один из подходов к выстраиванию процессов управления инцидентами ИБ – это создание центра оперативного управления ИБ компании (Security Operation Center), что является одним из инструментов, который позволяет быстро реагировать на возникающие инциденты, оперативно проводить их всесторонний анализ, эскалировать и обрабатывать инциденты согласно планам по их обработке и требованиям бизнеса, и контролировать эффективность процессов управления инцидентами ИБ.
Центр оперативного управления ИБ, как правило, является единой точкой для сбора информации о текущей ситуации в компании (с точки зрения ИБ) и ее контроля, единой точкой для эскалации инцидентов и взаимодействия с другими подразделениями компании – IT-службой, службой управления операционными рисками и др. Очень важно определить и четко регламентировать процессы и правила взаимодействия между подразделением ИБ и другими подразделениями компании и интегрировать их в планы коммуникаций в случае возникновения нештатных ситуаций.
Все этапы процесса управления инцидентами ИБ могут и должны быть полностью интегрированы и автоматизированы в рамках центра оперативного управления ИБ (см. рис. 2).

Таким образом, процессы управления инцидентами ИБ являются неотъемлемой частью комплексной системы обеспечения непрерывности бизнеса (ОНБ). Понимание важности создания системы ОНБ в целом, а также грамотное выстраивание процессов управления инцидентами и их интеграция в систему ОНБ позволят компании повысить свою стабильность за счет активного выявления проблем и потенциальных угроз, снизить ущерб от нештатных ситуаций за счет их своевременного выявления и быстрого реагирования, а также повысить свою конкурентоспособность с точки зрения надежного партнера и поставщика услуг. А создание центра оперативного управления ИБ (Security Operation Center) позволит снизить операционные затраты на процессы управления инцидентами ИБ и обеспечение непрерывности бизнеса и тем самым повысить эффективность системы ОНБ компании в целом.
Инциденты информационной безопасности – выявление и расследование

Хотя бы один раз за весь период работы большинство компаний сталкивалось с инцидентами информационной безопасности. Речь идет об одном, двух и более неожиданных и нежелательных событиях в корпоративной сети, которые приводят к серьезным финансовым и репутационным последствиям. Например, доступ третьих лиц к закрытой информации организации. К классическим примерам можно отнести значительное искажение инфоактивов, а также хищение персональных данных пользователей (клиентской базы, проектная документация).
Угрозы информационной безопасности — ключевые риски
Не только крупные корпорации, но и небольшие фирмы различных организационно-правовых форм и размеров время от времени сталкиваются с кибератаками. Количество пострадавших компаний ежегодно увеличивается. Действия злоумышленников приводят к большим убыткам пострадавших организаций.
Есть несколько основных рисков внутри корпораций и фирм:
- Уязвимость программного обеспечения;
- Доступ к конфиденциальной информации через работников;
- Пренебрежение основными правилами безопасности со стороны сотрудников, что приводит к непреднамеренной утечке корпоративной информации.
Основная проблема многих организаций в том, что в активно развивающемся мире киберугроз, большинство организаций даже не задумывается об информационной безопасности до возникновения инцидента. Поэтому часто нет резервных копий, доступ к данным есть у всех сотрудников, даже если они не пользуются ими в своей работе, а сеть ничем не защищена, и внедрить туда вредоносное ПО или заблокировать работу сервера организации может фактически любой желающий.
Классификация инцидентов
Аномалии, с которыми сталкиваются предприятия можно классифицировать по следующим признакам:
- Тип информационной угрозы;
- Уровень тяжести инцидентов для работы организации;
- Преднамеренность появления угрозы безопасности данных;
- Вероятность возникновения повторного «заражения» программного обеспечения;
- Нарушенные политики ИБ;
- Уровень системы организационных структур, обеспечивающих работу и развитие информационного пространства;
- Трудности обнаружения;
- Сложность устранения выявленной угрозы, которая может нарушить сохранность ценных данных компании.
Инциденты могут быть как умышленными, так и непреднамеренными. Если обратить внимание на первый вид инцидента, то он может быть спровоцирован разными средствами, техическим взломом или намеренным инсайдом. Оценить масштабы влияния на безопасность и последствия атаки крайне сложно. Утечки информации в виде баз данных на чёрном рынке оцениваются в миллионах рублей .
Существует категорирование инцидентов, позволяющее прописать их в политике безопасности и предотвращать их уже по первым признакам:
1. Несанкционированный доступ. Сюда стоит отнести попытки злоумышленников беспрепятственно войти в систему. Яркими примерами нарушения можно назвать поиск и извлечение различных внутренних документов, файлов, в которых содержатся пароли, а также атаки переполнения буфера, направленные на получение нелегитимного доступа к сети.
2. Угроза или разглашение конфиденциальной информации. Для этого нужно получить доступ к актуальному списку конфиденциальных данных.
3. Превышение полномочий определенными лицами. Речь идет о несанкционированном доступе работников к определенным ресурсам или офисным помещениям.
4. Кибератака, влекущая к угрозе безопасности. Если отмечается поражение вредоносным ПО большого количества ПК компании — то это не простая случайность. Во время проведения расследования важно определить источники заражения, а также причины данного события в сети организации.
Что делать при обнаружении инцидента?
Управление аномальными событиями в сети подразумевает не только оперативное обнаружение и информирование службы информационной безопасности, но и их учет в журнале событий. В журнале автоматически указывается точное время обнаружения утечки информации, личные данные сотрудника, который обнаружил атаку, категорию события, все затронутые активы, планируемое время устранения проблемы, а также действия и работы, направленные на устранение события и его последствий.
Современным компаниям ручной способ мониторинга инцидентов уже не подходит. Так как аномалии происходят за секунды и требуется мгновенное реагирование. Для этого необходимы автоматизированные решения по информационной безопасности, которые непрерывно мониторят все, что происходит в сети организации оперативно реагируют на инциденты, позволяя принимать меры в виде блокировки доступа к данным, выявления источника события и быстрого расследования, в идеале до совершения инцидента.
После расследования, выполняя правила корреляции, которые свидетельствуют о вероятных попытках причинения вреда безопасности данных подобными способами, создается карточка данного инцидента и формируется политика безопасности. В дальнейшем подобные атаки будут подавлены и приняты меры до совершения активных действий со стороны сотрудников и внешних источников угроз.
Реагирование на утечку данных
При обнаружении нарушений в сети организации рекомендован следующий алгоритм действий со стороны службы информационной безопасности:
1. Фиксация состояния и анализ информационных ресурсов, которые были задействованы.
2. Координация работы по прекращению влияния информационных атак, проведение которых спровоцировало появление инцидента.
3. Анализ всего сетевого трафика.
4. Локализация события.
5. Сбор важных данных для установления причин происшествия.
6. Составление перечня мер, направленных на ликвидацию последствий инцидента, который нанес урон.
7. Устранение последствий.
8. Контроль устранения последствий.
9. Создание политик безопасности и подробного перечня рекомендаций, направленных на совершенствование всей нормативной документации.
Выявление причин инцидента безопасности
Анализ ситуации позволяет оценить риски и возможные последствия инцидента.
После того, как последствия события полностью устранены, обязательно проводится служебное расследование. Оно требует привлечения целой команды опытных специалистов, которые самостоятельно определяют порядок изучения фактов и особенностей произошедшего. Дополнительно используются всевозможные публичные отчеты, аналитические средства, потоки сведений обо всех угрозах, а также другие источники, которые могут пригодиться в процессе изучения конкретного кейса. Квалифицированные специалисты устраняют вредоносное программное обеспечение, закрывают возможные уязвимости и блокируют все попытки нелегитимного доступа.
По факту расследования составляют перечень мер, направленных на профилактику аналогичных кибератак. Дополнительно составляется список действий моментального реагирования в случае, если имело место проникновение вредоносного ПО в систему. Нужно провести обучение персонала фирмы для повышения киберграмотности.
Решения для информационной безопасности организации
Для предотвращения инцидентов ИБ необходимо внедрить специализированные решения, способные в реальном времени выявлять и реагировать на них даже по первым признакам до непосредственного хищения или других мошеннических действий.
«Гарда Технологии»- российский разработчик систем информационной безопасности от внутренних и внешних угроз, который предлагает комплексные решения по защите от утечек информации, защите баз данных и веб-приложений, защите от DDoS-атак и анализу и расследованию сетевых инцидентов. Решения интегрируются друг с другом, образуя комплексное решение — экосистему безопасности.
Внедрение решений по информационной безопасности позволяет избежать многочисленных финансовых и репутационных рисков.
Источник https://www.ptsecurity.com/ru-ru/research/analytics/incidents-siem-2020/
Источник https://lib.itsec.ru/articles2/control/ne-prervat-svyazuyuschiy-protsess—ili-esche-raz-o-nepreryvnosti-biznesa-i-o-roli-upravleniya-intsidentami
Источник https://gardatech.ru/articles/smi/intsidenty-informatsionnoy-bezopasnosti-vyyavlenie-i-rassledovanie/


